|
A platform for high-performance distributed tool and library development written in C++. It can be deployed in two different cluster modes: standalone or distributed. API for v0.5.0, released on June 13, 2018.
|
|
A platform for high-performance distributed tool and library development written in C++. It can be deployed in two different cluster modes: standalone or distributed. API for v0.5.0, released on June 13, 2018.
|
#include <QuerySchedulerServer.h>
 Inheritance diagram for pdb::QuerySchedulerServer: Collaboration diagram for pdb::QuerySchedulerServer:
Inheritance diagram for pdb::QuerySchedulerServer: Collaboration diagram for pdb::QuerySchedulerServer:Public Member Functions | |
| QuerySchedulerServer (PDBLoggerPtr logger, ConfigurationPtr conf, std::shared_ptr< StatisticsDB > statisticsDB, bool pseudoClusterMode=false, double partitionToCoreRatio=0.75) | |
| QuerySchedulerServer (int port, PDBLoggerPtr logger, ConfigurationPtr conf, std::shared_ptr< StatisticsDB > statisticsDB, bool pseudoClusterMode=false, double partitionToCoreRatio=0.75) | |
| ~QuerySchedulerServer () | |
| void | registerHandlers (PDBServer &forMe) override |
| void | collectStats () |
| void | cleanup () override |
| StatisticsPtr | getStats () |
| std::string | getNextJobId () |
| Public Member Functions inherited from pdb::ServerFunctionality | |
| template<class Functionality > | |
| Functionality & | getFunctionality () |
| void | recordServer (PDBServer &recordMe) |
| PDBWorkerPtr | getWorker () |
| PDBLoggerPtr | getLogger () |
Protected Attributes | |
| std::vector < StandardResourceInfoPtr > * | standardResources |
| int | port |
| std::vector< Handle < SetIdentifier > > | interGlobalSets |
| PDBLoggerPtr | logger |
| ConfigurationPtr | conf |
| std::shared_ptr< StatisticsDB > | statisticsDB |
| bool | pseudoClusterMode |
| pthread_mutex_t | connection_mutex |
| SequenceID | seqId |
| std::string | jobId |
| double | partitionToCoreRatio |
| std::shared_ptr < PhysicalOptimizer > | physicalOptimizerPtr |
| StatisticsPtr | statsForOptimization |
| std::shared_ptr< ShuffleInfo > | shuffleInfo |
This class is working on the Manager node to schedule JobStages dynamically from TCAP logical plan So far following JobStages are supported:
– TupleSetJobStage – AggregationJobStage – BroadcastJoinBuildHTJobStage – HashPartitionJoinBuildHTJobStage
Once the QuerySchedulerServer receives a request (A TCAP program) in the form of an
Definition at line 62 of file QuerySchedulerServer.h.
| pdb::QuerySchedulerServer::QuerySchedulerServer | ( | PDBLoggerPtr | logger, |
| ConfigurationPtr | conf, | ||
| std::shared_ptr< StatisticsDB > | statisticsDB, | ||
| bool | pseudoClusterMode = false, |
||
| double | partitionToCoreRatio = 0.75 |
||
| ) |
Constructor for the case when we assume that the port where we are running the server is 8108
| logger | an instance of the PDBLogger |
| conf | |
| pseudoClusterMode | indicator whether we are running in the pseudo cluster mode or not |
| partitionToCoreRatio | the ratio between the number of partitions on a node and the number of cores |
Definition at line 43 of file QuerySchedulerServer.cc.
| pdb::QuerySchedulerServer::QuerySchedulerServer | ( | int | port, |
| PDBLoggerPtr | logger, | ||
| ConfigurationPtr | conf, | ||
| std::shared_ptr< StatisticsDB > | statisticsDB, | ||
| bool | pseudoClusterMode = false, |
||
| double | partitionToCoreRatio = 0.75 |
||
| ) |
Constructor for the case when where we specify the port number of the server
| port | is the port on which the server that contains this functionality is running |
| logger | an instance of the PDBLogger |
| conf | |
| pseudoClusterMode | indicator whether we are running in the pseudo cluster mode or not |
| partitionToCoreRatio | the ratio between the number of partitions on a node and the number of cores |
Definition at line 61 of file QuerySchedulerServer.cc.
| pdb::QuerySchedulerServer::~QuerySchedulerServer | ( | ) |
Destructor used to destroy the QuerySchedulerServer
Definition at line 39 of file QuerySchedulerServer.cc.
|
overridevirtual |
Cleans up the query scheduler server so it can be used for the next computation
Reimplemented from pdb::ServerFunctionality.
Definition at line 79 of file QuerySchedulerServer.cc.
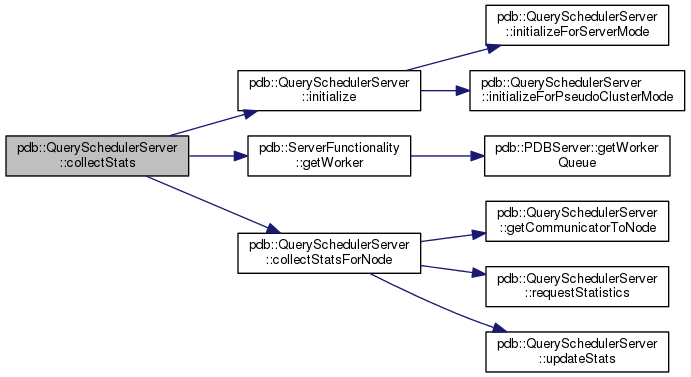
Here is the caller graph for this function:| void pdb::QuerySchedulerServer::collectStats | ( | ) |
Collects the statistics about the sets from each node and updates them [statsForOptimization]
Definition at line 452 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
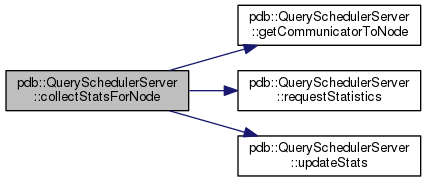
Collects the stats for one node
| node | the node we are collecting the stats for |
| counter | the counter that is increased when we are finishing updating the stats |
| callerBuzzer | the buzzer that signals that we are finished |
Definition at line 491 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
Given a vector of SetIdentifiers this method issues their creation
| dsmClient | an instance of the DistributedStorageManagerClient that needs to create the sets |
| intermediateSets | the vector of intermediate sets |
Definition at line 803 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
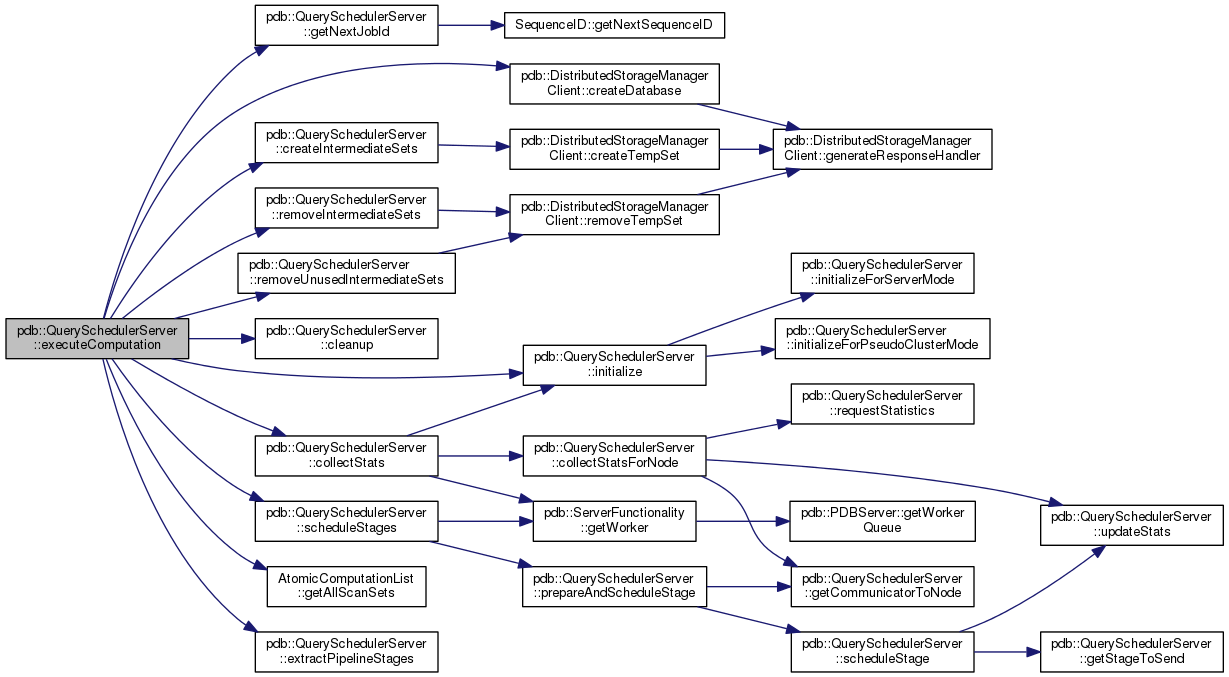
protected |
This method executes a PDB computation given by the ExecuteComputation object, that was sent by a client
| request | the object that describes the computation |
| sendUsingMe | an instance of the PDBCommunicator that points to the client |
do the physical planning
create intermediate sets
schedule this job stages
Definition at line 633 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
This method finds the best source operator using a heuristic, then uses this operator to extract a sequence of of pipelinable stages.
| jobStageId | the of last executed job stage |
| jobStages | a vector where we want to store the sequence of jobStages |
| intermediateSets | a vector where we want to store the information about the intermediate sets that need to be generated |
Definition at line 829 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
protected |
Connects to the node with the provided ip and port and returns an instance of the communicator
| port | the port of the node |
| ip | the ip address of the node |
Definition at line 272 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
inline |
Returns the id of the job we are about to run Has the following format Job_Year_Month_Day_Hour-Minute_Second_{Next number from the seqId sequence generator}
Definition at line 127 of file QuerySchedulerServer.h.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
Makes a deep copy of the TupleSetJobStage, fills in additional information about the node we are sending it and returns it
| stage | an instance of the TupleSetJobStage |
Definition at line 342 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
protected |
Makes a deep copy of the AggregationJobStage, fills in additional information about the node we are sending it and returns it
| stage | an instance of the AggregationJobStage |
Definition at line 387 of file QuerySchedulerServer.cc.
|
protected |
Makes a deep copy of the stage provided and detaches it from the logical plan, by setting it to null and fill in additional information about the node we are sending it to
| stage | an instance of the BroadcastJoinBuildHTJobStage |
Definition at line 411 of file QuerySchedulerServer.cc.
|
protected |
Makes a deep copy of the stage provided and detaches it from the logical plan, by setting it to null and fill in additional information about the node we are sending it to
| stage | an instance of the HashPartitionedJoinBuildHTJobStage |
Definition at line 427 of file QuerySchedulerServer.cc.
| StatisticsPtr pdb::QuerySchedulerServer::getStats | ( | ) |
Returns the statistics that are being used for optimization
Definition at line 158 of file QuerySchedulerServer.cc.
|
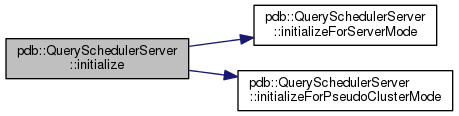
protected |
Initializes the QuerySchedulerServer more specifically the
Definition at line 92 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
TODO Ask Jia what the difference is between a resource and a node add a proper description
Definition at line 107 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
protected |
TODO Ask Jia what the difference is between a resource and a node add a proper description
Definition at line 131 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
protected |
This method takes in an
| stage | the stage we want to send |
| node | the node we want to send the stage to |
| counter | a reference to the counter that needs to be increased once the execution of the stage is complete |
| callerBuzzer | the buzzer we use to notify the calling thread that we are done executing |
Definition at line 200 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
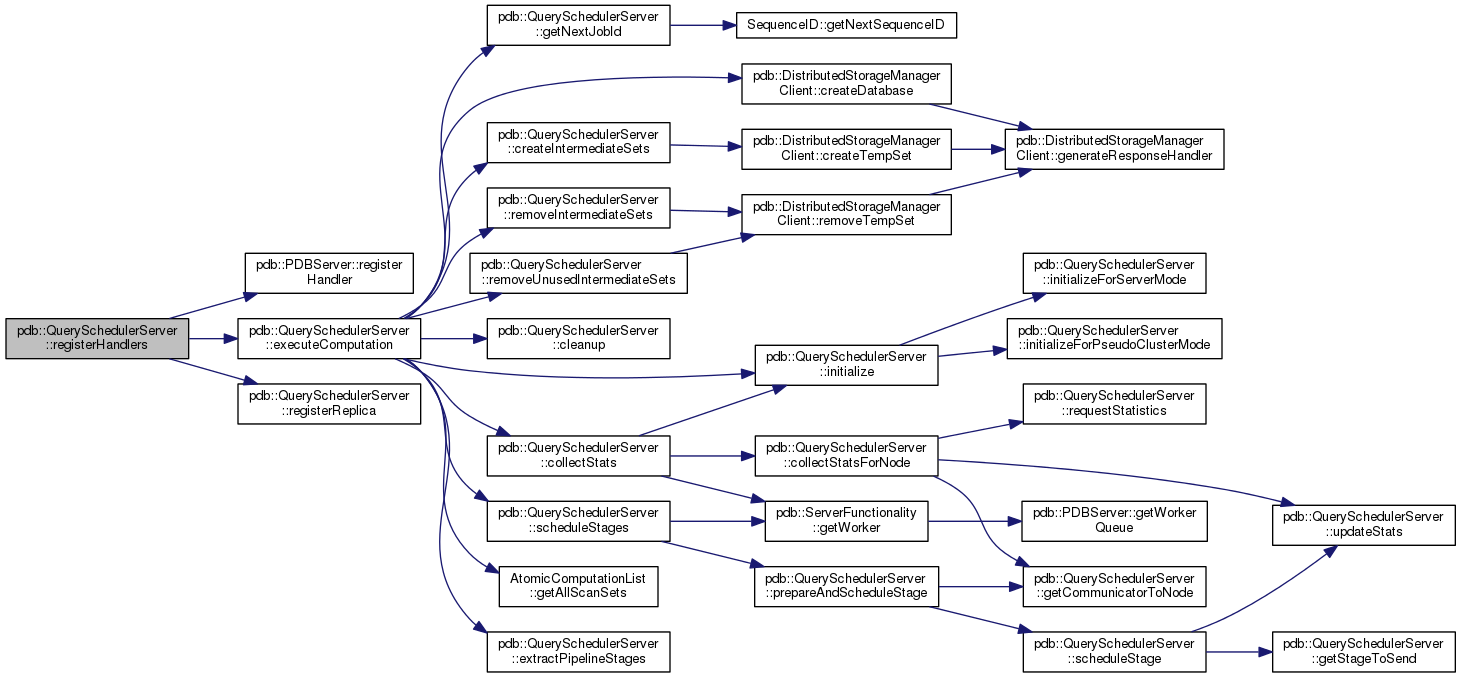
overridevirtual |
This method is from the serverFunctionality interface... It register the query scheduler handlers to the provided server
Implements pdb::ServerFunctionality.
Definition at line 573 of file QuerySchedulerServer.cc.
Here is the call graph for this function:
|
protected |
This method registers a replica with statisticsDB per client request
| request | the object that describes the computation |
| sendUsingMe | an instance of the PDBCommunicator that points to the client |
Definition at line 595 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
protected |
This method removes all the intermediate sets that we needed to continue our execution They are kept in the interGlobalSets vector
| dsmClient | an instance of the DistributedStorageManagerClient that needs to remove the sets |
Definition at line 779 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
Given a vector of SetIdentifiers this method issues their removal Sets that are going to be used later in the execution are not removed, they are cleaned up with the method
| dsmClient | dsmClient an instance of the DistributedStorageManagerClient that needs to remove the sets |
| intermediateSets | the vector of intermediate sets |
Definition at line 746 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
This method takes in a communicator to a node and issues a request for statistics about the stored sets
| communicator | the communicator to the node |
| success | a reference a boolean that will set to true if the request succeeds, false otherwise |
| errMsg | the error message that is gonna be set, if an error occurs |
Definition at line 550 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
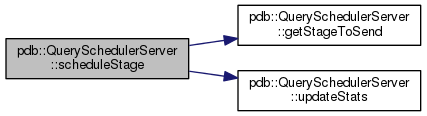
protected |
This method schedules a pipeline stage given the index of a specified node and a communicator to that node.
| node | is the index of the node we want to schedule the stage |
| stage | is the pipeline stage we want to schedule |
| communicator | is the communicator to a node we are going to use for that |
Definition at line 302 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
This method is used to schedule dynamic pipeline stages It must be invoked after initialize() and before cleanup()
| stagesToSchedule | is a vector of all the stages we want to schedule |
| shuffleInfo | is the shuffle information for job stages that needs repartitioning |
Definition at line 163 of file QuerySchedulerServer.cc.
Here is the call graph for this function: Here is the caller graph for this function:
|
protected |
Updates the optimization stats for a given set
| setToUpdateStats | the set we are updating (contains also info about the pages and size) |
Definition at line 555 of file QuerySchedulerServer.cc.
Here is the caller graph for this function:
|
protected |
The configuration of the node provided by the constructor
Definition at line 339 of file QuerySchedulerServer.h.
|
protected |
This is used to synchronize the communicator More specifically the part where we are creating them and connecting them to a remote node with the connectToInternetServer method
Definition at line 356 of file QuerySchedulerServer.h.
|
protected |
Set identifiers for shuffle set, we need to create and remove them at scheduler, so that they exist at any node when any other node needs to write to it
Definition at line 329 of file QuerySchedulerServer.h.
|
protected |
The id of the current job. Used to identify the job and the database for it's results
Definition at line 367 of file QuerySchedulerServer.h.
|
protected |
An instance of the PDBLogger set in the constructor
Definition at line 334 of file QuerySchedulerServer.h.
|
protected |
Used to calculate the the number of partitions on a node, based on the number cpu cores on that node more specifically partitionToCoreRatio = numPartitionsOnThisNode/numCores
Definition at line 373 of file QuerySchedulerServer.h.
|
protected |
An instance of the PhyscialAnalyzer. We use it to do the dynamic planning. More specifically to find the source that is we should start from using heuristics and to generate pipeline stages starting from this source
Definition at line 380 of file QuerySchedulerServer.h.
|
protected |
The port through which we access the functionalities on this node (port the PDBServer listens to)
Definition at line 323 of file QuerySchedulerServer.h.
|
protected |
True if we are running PDB in pseudo cluster mode false otherwise
Definition at line 349 of file QuerySchedulerServer.h.
|
protected |
Used to generate a unique sequential ID getNextSequenceID is thread safe to call
Definition at line 362 of file QuerySchedulerServer.h.
|
protected |
Wraps shuffle information for job stages that needs repartitioning data
Definition at line 394 of file QuerySchedulerServer.h.
|
protected |
A vector containing the information about the resources of each node
Definition at line 318 of file QuerySchedulerServer.h.
|
protected |
A pointer to StatisticsDB that manages various statistics
Definition at line 344 of file QuerySchedulerServer.h.
|
protected |
Contains the information about every set on every node, more specifically :
Definition at line 389 of file QuerySchedulerServer.h.
 1.8.6
1.8.6